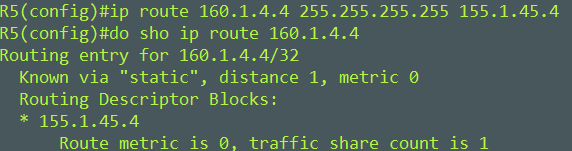
EIGRP Classic metrics couldn’t differentiate between anything faster than 10 Gigabit Ethernet interfaces.
Below is the EIGRP classic composite metric
EIGRP composite cost metric = 256*((K1*Scaled Bw) + (K2*Scaled Bw)/(256 – Load) + (K3*Scaled Delay)*(K5/(Reliability + K4)))
This can be simplified to 256*(Scaled Bw + Scaled Delay)
Here is a break down of what this means
EIGRP uses one or more vector metrics in the calculation of the composite cost metric (the formula above), here they are.
Bandwidth
Delay
Load
Reliability
Out of these vector metrics Bandwidth and Delay are the most commonly used to produce the composite cost metric.
Metric weights are monitored by K values. The K values are integers from 0 to 128. The integers and the vector metrics, most commonly (bandwidth and delay) are used to calculate the overall EIGRP composite cost metric.
K1 and K3 are the only default constants used in the composite formula. (There are 5 K values) – K1,K3 = 1 K2,K4,K5 = 0
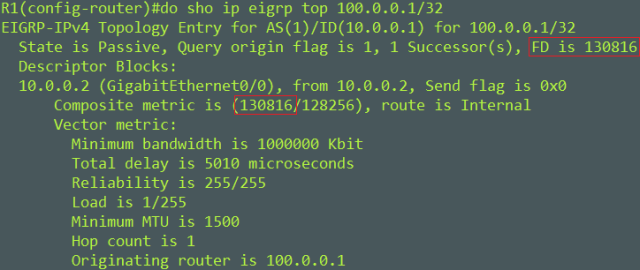
Here’s an example

We want to find the composite metric between R1 and R2s lo100 – 100.0.0.1/32
First we need to get the Scaled Bandwidth with the below formula. The bandwidth of the link is 1G.
Scaled Bw = 10^7 / Interface Bandwidth
We have to express the 1G interface in Kilobits. Formula would look like this.
Scaled Bw = 10^7 / 1000000
Scaled Bw = 10000000 / 1000000
Scaled Bw = 10
Second we need to find the Scaled Delay with the below formula. The Delay is 5010 microseconds.
Scaled Delay = (Delay/10)
Scaled Delay = (5010/10)
Scaled Delay = 501
Note: Delay is cumulative along the path to the destination prefix.
Now we can fill in our simplified composite formula
256*(10 + 501) = 130861
Composite metric is 130861
EIGRP wide metrics were introduced to assist in scaling for high bandwidth interfaces. EIGRP wide metrics offer the following:
- 64 – bit metric calculation (compared to the 32 – bit metric of Classic EIGRP)
- 128 – bit metric for the RIB
- 65536 – Base Metric (compared to 256)
- Bandwidth express in picoseconds (compared to tens of microseconds)
- K6 ( reserved for future use and are known as “Extended Metrics”)
Here is the wide metric formula
Metric = [(K1*Minimum Throughput + {K2*Minimum Throughput} / 256-Load) + (K3*Total Latency) + (K6*Extended Attributes)]* [K5/(K4 + Reliability)]
Bandwidth is now Throughput
Delay is now Latency.
Because we now have a larger base metric (65536) we can now account for higher speed links and because we use picoseconds this fixes delay issues.
Here are the simplified formulas for computing the composite cost metric. The vector metrics we care about are Throughput and Latency.
Composite Cost Metric = (K1*Minimum Throughput) + (K3*Total Latency)
To find Minimum Throughput use
Minimum Throughput = (107* 65536)/Bw)
For Total Latency interfaces under 1 Gigabit use
Total Latency for bandwidths below 1 gigabit = (Delay*65536)/10
For Total Latency interfaces above 1 Gigabit use
Total Latency for bandwidths above 1 gigabit = (107* 65536/10)/ Bw
Lastly once you have your Composite cost metric divide it by the RIB metric of 128. This is so that the 64-bit metric calculation can fit into the RIB.
1392640 / 128 = 10880 – This is what will be installed into the RIB

Some take aways
Although you can configure K values to produce varying routing behaviors, most configurations use only the delay/latency and bandwidth/throughput metrics by default so its best to keep K values to their defaults. Changing these could have a larger affect on more than just the EIGRP metric, for exmaple QoS will use these K values and if changed could have undesirable results.
It’s best to change the delay of the link to influence path selection, rather than changing the bandwidth. Changing the bandwidth could have a larger affect on more than just the EIGRP metrics.
K values still need to match between routers to form adjacency.
Mike